If any of your customer or employees expect a web site or service to be available--if in fact it is worth having up at all--then it is worth monitoring. If you're responsible for a service being up, make it easy on yourself by always knowing before your users start to tell you when something needs attention.
If you are only monitoring from inside your own infrastructure, you are not getting the full picture you need about the availability of your services to customers. On premise monitoring is useful as well, and we have tools for that, but monitoring from across the Internet from systems that are not dependent on your infrastructure is essential. Even for your internal monitoring, you should be able to receive notifications and access the data about your monitoring from anywhere, any time.
This goes along with the last point. Your server monitoring should be independent of problems in any one location. Many monitoring services, including NodePing, have this built in by rechecking automatically from multiple geographically diverse locations. Diverse geographical locations for probes should be a basic requirement of your availability monitoring.
One of the biggest problems with some notification systems is getting too many notices. We'd all like every web site to respond within two seconds every time, but setting the threshold too close to the normal performance level can give you notifications that you don't really need to do anything about immediately. It becomes very hard for even the most diligent System Admin not to start to ignore them. If you start ignoring notifications, at some point you will miss the one that mattered. NodePing's systems are designed to avoid unnecessary notifications, but the threshold and sensitivity settings are there to help adjust the notifications to a level that is appropriate for each host. Our delayed notifications feature will also help with flapping services. You should use these to tune the checks correctly for each service, so that you get notifications you need, but not notifications you will train yourself to ignore.
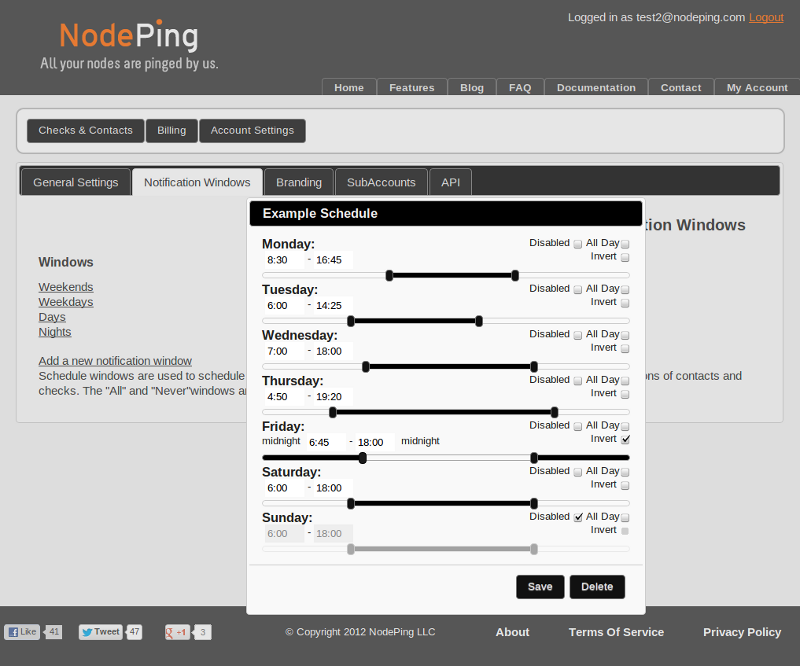
Along with tuning the sensitivity and threshold for checks, it is important to make sure that notifications that are sent are going to the right person. That means that in the evening and on weekends, for example, they shouldn't go to the guy who is supposed to relaxing with his wife and kids then instead of responding to alerts. Use the scheduling windows to make sure that the notifications are going to the person who is supposed to respond to problems during that time period, and to the right address for that person.
Enable automated diagnostics to get a bounty of detailed technical information about the failure and additional diagnostics based on the failure time. A 'timeout' failure will trigger an MTR from each probe that verified the failure. If DNS is failing, we'll give you dig outputs for each of the nameservers. Use this info to help you troubleshoot quickly and get your service back up and running fast.
This isn't a technical point, but it is important. You can easily spend more than you have to on server and site monitoring. We think people should shop around for the features and price they need, but if you are ever deciding not to monitor a service because it costs too much, you are paying too much for your monitoring service. NodePing is priced to make it a solid value for the real benefit to your business.
Many people think of monitoring as mostly about website monitoring, but it goes much further than just websites. NodePing has over 25 different monitoring check types. What could you do with monitoring when it is easy and cost effective enough to let you monitor everything? Get creative, and use the service to improve what you provide to your customers as well.

 Documentation
Documentation Development
Development Premiere
Premiere Check Types
Check Types