Notifications are a key piece of any monitoring service. They are used to alert the correct person, the correct way, so they can react to service interruptions in a timely manner before very many of your customers or users are impacted.
It's important that every notification sent be 'actionable' - meaning it requires a person or system to react to it. Notifications just for information's sake lead to alert fatigue and your on-call responders begin to ignore notifications because of the noise.
Our goal in designing the notification system for NodePing was to make sure you are notified of status changes in your sites or services only when action is needed. Some services are prone to flapping and if you only need to take action if the services has been down for, say, 5 minutes, you should only receive alerts at that point. Other services may require immediate response by sysadmins and if the service hasn't recovered after say, 15 minutes, a manager should be alerted as well. You can set such delays for each contact and each check in NodePing. If the service recovers before the configured delay, no notification will be sent.
NodePing's notification system is configurable enough to provide only actionable alerts and flexible enough to alert your contacts by the methods that are most effective for them. When setting notifications on your checks, be sure to choose the right contact method or group and the right message delay for when the notification will be immediately actionable for each contact.
There are other pieces of the puzzle involved with making sure that every notification is actionable. The most important is tuning your check settings. If you set the check threshold setting too low, for example, you may get notices that don't give you any useful information (useful here meaning that if you get a notification, there is something you should do to the service immediately). Generally you should set the threshold to tell you when there is a problem that requires an immediate response, and use the reports to see if your website performance is acceptable. Setting the threshold low to notify you when the site is a little slow usually leads to alert fatigue and ignoring notifications.
NodePing site monitoring services include unlimited international SMS and email notifications. Most checks use email notifications. SMS is typically used for notifications on services that are more time critical, or at times of day when email is likely to not be seen for several hours (especially at night).
Professional and Premiere accounts allow you to customize the content of SMS and Email notifications for your customers. See our Branding documentation for more.
By default, "Up" and "Down" email notifications have different subject lines so you can easily see what is happening just from the subject lines. For some people, it is more important to have the "Up" and "Down" messages appear together in an email thread. Most email clients will display them as a thread if the subject lines are identical. If that is what you want, use the Branding configuration to set your "Up" and "Down" subject lines to be the same.
Get push notifications from Pushover on your iOS and Android devices. Default 'Emergency' notifications are sent when a check fails and will automatically re-alert every 30 seconds until the notification is acknowledged, up to 5 minutes. Try sleeping through that! Pushover notifications are faster and more reliable than SMS and also allow NodePing to keep prices low. Please consider using Pushover notifications instead of SMS. You can download Pushover to your device from the appropriate app store and then enter your user key in the notification type text box and choose 'Pushover' from the drop down menu. Select the Pushover key you entered when creating or editing a check and you will receive notifications on each check event. You can also set your preferred notification level offered by Pushover.
The Premiere plan includes unlimited voice notifications worldwide. We'll call your phone and a soothing robotic voice will calmly tell you that your server is down... or that it has come back up. You'll need a specific entry in your contact record for each voice number. Enter the voice number and select 'Voice' from the dropdown.
Webhooks are user-defined HTTP requests that allow you to integrate our event notifications with other services and systems. NodePing webhook notifications are included in our Professional and Premiere plans.
The default webhook HTTP action is GET. If you only set a webhook URL, our service will add the following default information to the query string.
We support HTTP GET, POST, PUT, DELETE and HEAD methods. We also provide a form for entering query string keys and values. Arbitrary headers can be added and if POST or PUT actions are specified, you can define an HTTP body payload (JSON, text, XML, whatever) and set the 'Content-Type' header to match. The payload will not be sent if the HTTP method is set to GET, DELETE, or HEAD. You can optionally set BASIC Auth in the URL or in the 'Authorization' header.
Query string and body payload values can be templated to substitute values from the check information and its result. A type-ahead is available for the query string value fields using the curly brace "{". You can also use these directly in the query string of the URL like:
https://example.com/mywebhook.php?upOrDown={event}'
When the check fails, the above {event} will be replaced with 'down' like so:
https://example.com/mywebhook.php?upOrDown=down'
When the check recovers, the {event} will be replaced with 'up'.
https://example.com/mywebhook.php?upOrDown=up'
We also support limited conditionals statements in our templates (but not in the URL query string). For example:
{if su}checkfailing=no{else}checkfailing=yes{/if}
We offer a couple Webhook presets in a Preset Services dropdown menu for customers who want to easily integrate with these third party service. Currently those are:
In addition to the template values listed above, check information template values can be found in our API documentation
Integrate your PagerDuty notifications with NodePing server monitoring. Our system will send a 'trigger' event on each failure and a 'resolve' on each recovery. You'll need to use a 'Generic API Service' in your PagerDuty account and add an entry in your contact record by specifying your PagerDuty 'Service API Key' and selecting 'PagerDuty' in the notification type drop down. You can specify as many different PagerDuty contacts as you like. This allows you to use multiple 'Services' and have full control of your PagerDuty escalations and notifications. This notification type is currently only available on Professional and Premiere plans.
Receive NodePing notifications in your preferred Slack channel. Set up an incoming webhook in your Slack account and put the webhook URL into your 'Slack' notification contact to receive 'down' and 'up' messages on the configured channel. This notification type is currently only available on Professional and Premiere plans and uses the 'email' branding template.
Receive NodePing notifications in a HipChat room. Set up a "Build your own integration" webhook in your HipChat account and put the webhook URL into your 'HipChat' notification contact to receive messages in the configured room. This notification type is currently only available on Professional and Premiere plans and uses the 'email' branding template.
The Sensitivity setting on NodePing checks puts two considerations into one simple setting. The setting configures how many times NodePing should recheck a service before sending notifications that it is down. The first part of this is "flapping." Flapping occurs when a service is rapidly changing between up and down states. This happens particularly on shared web hosts, when some other site is consuming resources on the same server as the monitored site, or other similar situations in which the available resources to provide the service are marginal. If the monitoring checks notify on a single check result in those situations, notifications will be sent out when the site appears to be "up." These problems are often very transient, and lead to notifications that aren't really very actionable especially if you are already aware that the server is prone to this type of issue. Setting the Sensitivity lower causes NodePing to recheck the service more times before reporting it as down. The number of rechecks for each level of Sensitivity are:
The rechecks happen a few seconds apart, so that on a setting of "Very Low" a site can be down for approximately 90 seconds before it is marked as down and we send a notification. Sometimes that's exactly what you want, but most often a Sensitivity setting of "High" is best. "High" ensures that the check didn't fail for very transient reasons (such as a router hiccup somewhere), but that the notification is still sent promptly, typically within 30 seconds of the original scheduled check time.
The second consideration in rechecks is check location. When NodePing detects that the status of a service has changed, it automatically reschedules rechecks to occur in a different location. It is uncommon, but sometimes a check can fail because of something unrelated to the service being monitored. For example, a router in between the NodePing probe and the website could be acting up. Getting a notification because one random router out on the Internet somewhere is having problems is not usually actionable. So, NodePing rechecks the service from a server at a different geographic location to make sure the cause of the status change is really the service being monitored and not a local probe issue. For example, if a check is set to "High" Sensitivity and a check from New Jersey shows that it is down, the system will automatically run the rechecks in other places. The first recheck might be in Texas, and the third in California. The recheck's location is not predictable, the system just sets it to run "elsewhere." We do that to enable multi-site rechecks without complicating the service's check configuration. As a result, as long as your Sensitivity is not set to "Very High" (which skips rechecks and just sends the notification immediately - not recommended), you automatically get geographically dispersed rechecks without any further configuration required.
Many services require notifications 24 hours a day, seven days a week. For those services, the default "Always" setting for notifications works great, and configuring the monitoring is simple. For other services, you want notification to a particular person during a certain time of day, and notification to someone else during a different time of day. Often these correspond to different people's work schedules or an on-call rotation. You might want email during work hours and SMS after hours. Some services only need notifications to be sent if they are down during office hours, and others only if they are down when someone is not already paying attention. All of these different notification needs led to NodePing's notification scheduling functionality. We think the service provides a good balance between flexibility, to handle all these different needs, and simplicity in the amount of configuration you need to do to get it set up.
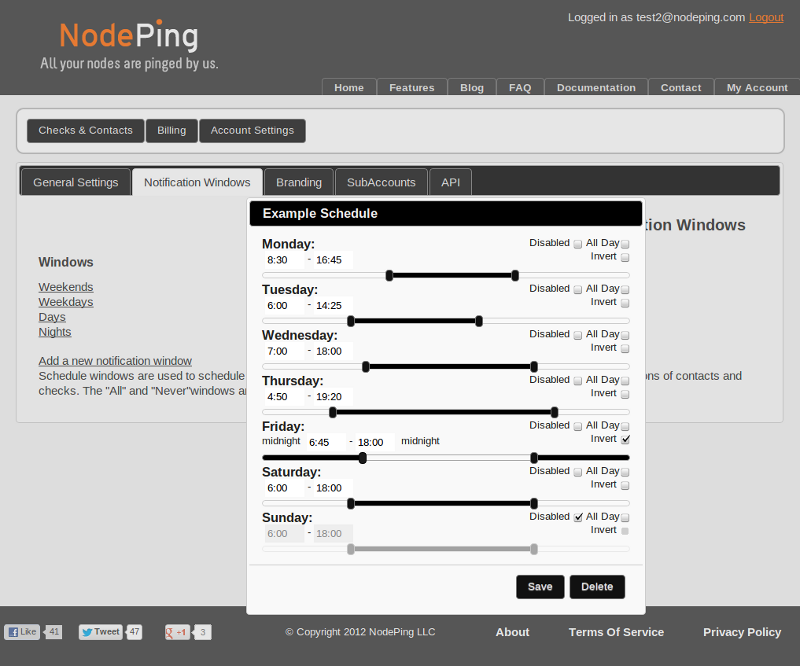
NodePing provides five notification scheduling "windows" by default: Weekends, Weekdays, Days, Nights, Always, and Never. You can customize all of these for your specific account except for Always and Never. You can also add additional notification windows. For example, you might want a schedule for the swing shift or evenings, or something unique to your company. Some schedules include notifications all day (midnight to midnight), some days, and none at all other days. The opposite of that is to have some days with no notifications at all, which uses the "Disable" toggle for that day. Weekends and Weekdays are examples that use both of those settings. The Invert toggle is used to cause notifications to be sent at all times except for a certain window. This is used for the Nights schedule, which is intended to schedule notifications at all times other than business hours. All of these are completely optional, and can be adjusted to meet your specific needs.
You may have services that often fail but recover quickly without any action on your part. Receiving notifications for flapping services is not only annoying but can lead to you ignoring alerts, even important ones. Set a delay on your notifications to allow time for flapping services to recover before sending out alerts. You can also use delayed notifications as a way to provide alert escalations. For example, if service X fails, you can configure NodePing to send an email immediately and if the service is still offline after 10 minutes, send an SMS. And if the service hasn't been restored after 30 minutes, a voice call is sent to your manager to escalate the outage. The important point is to only send notifications, delayed or immediate, when they are actionable.
Set a delay using the dropdown next to each contact method in the Check Notifications section of the check edit dialog. It defaults to no delay (Immediate).
Choose an active check from the dropdown in the check edit dialog and if that selected check is already failing, notifications will not be sent for this check. We encourage you to monitor everything - PING check for your routers, SSH checks for your servers, HTTP checks for each website, etc. When a network or server outage occurs, that can trigger a lot of notifications for services that rely on that underlying network or server. It can be distracting during an outage to receive dozens of alerts for websites and email services that will fail when a switch goes offline. To help reduce the number of notifications you receive for dependent services, set a notification dependency.
The Notifications Settings tab in your Account Settings provides a button to suppress all notifications for all contacts on your account. Use this feature to disable all notifications when a widespread outage or maintenance window is occurring and NodePing notifications would be a distraction. Use the link in the same area to re-enable notifications. Note, this will not effect your subaccounts and will not re-enable notifications for contacts that have been suppressed by other means.
You can mute all notifications on a check or for a particular contact method by clicking on the 'Mute' links either in the check edit dialog or in the contacts list. Click on 'Unmute' to re-enable notifications.
It is also possible to individually disable certain types of notifications. Some of these settings require use of the API. If you would like help understanding how these work or with setting them, please contact support and we'll be happy to help you. You can also disable the initial welcome message new contacts will receive in the Branding configuration.
The Notifications Settings page also allows you to set the time zone for your account. This time zone setting is just used for notifications and scheduling windows. Take note that if your time zone observes Daylight Savings Time or DST that NodePing does not automatically adjust your time zone setting as it is an offset of GMT. Please be sure to adjust your timezone if you observe DST. For time actually displayed on reports and graphs your computer's time zone is used automatically by your browser and will reflect DST if your computer does.
You can group contacts together to help manage on-call schedules or vacations. For instance, we have a group called "SysAdmin Email", when a system administrator goes on vacation, her email is removed from that group and she will no longer receive notifications that are assigned to that group. When she returns, we simply add her email contact method to the group and she'll start receiving notifications again. It's an excellent way to modify who gets notifications without having to edit any checks. The contact groups can be assigned either directly in check notifications or in notification profiles.
Notification profiles takes the concept of Contact Groups one-step further and allows you set contact methods and groups, along with delays, and schedules all in one place. Configuring all the notification settings in a notification profile and then assigning that profile to checks allows you to modify everything about the notifications without ever having to edit any checks.

 Documentation
Documentation Development
Development Premiere
Premiere Check Types
Check Types